Not Sigmoids, Not Exponentials
What a real model would look like (Part 1: Sornette and the dragon-king)
Part 2 is here
I left Contra Scott Alexander on Sigmoids on a demand:
Why aren’t more people demanding models that specify, in advance, the conditions under which they would consider themselves wrong?
And I said that I didn’t really have a model to offer (well, the article was getting long, and the obvious move is to make a follow up article offering some alternatives. This article is gonna be long, too…)
So in a series of pieces, I’ll surface the work of four people who already built much of what we need, and whose frameworks have been available the whole time the AI forecasting discourse has been arguing about curve shapes. Each developed their machinery for systems other than AI, but the architectures transfer with no major modifications.
The reason these models get largely missed in the AI capability conversation is partly that they sit in different intellectual lineages. The complex-systems literature, the forecasting-evaluation literature, and the systems-thinking literature each have their own conferences, their own canons, and their own vocabularies. Cross-pollination requires effort and time to percolate. And, the parameters are often difficult to choose - these are not trivial models to port over.
Recent academic papers — check out the November 2025 arXiv paper by Jafari et al.[1] modeling AI singularity as finite-time blow-up of a capability process — shows that adjacent literatures have been doing related work for years.
Didier Sornette and the Self-Generating Falsifier
A core criterion from the prior piece was that a valid model must commit to enough structure that its failures register as failures rather than as routine parameter adjustments. The example was Newton’s prediction of Mercury’s perihelion: specific enough that reality could disagree, and reality did.
Sornette’s Log-Periodic Power Law Singularity model is the closest thing in the complex-systems literature to a forecasting framework that does this on purpose, by construction. Sornette is a physicist at ETH Zürich who spent thirty years building tools to predict regime changes in nonlinear systems: applying to financial bubbles, earthquakes, material failures, epileptic seizures, and ecosystems. The LPPLS model fits a specific functional form to the run-up phase of a bubble. The functional form has a finite-time singularity built into it. The model commits to a date range within which the regime change will occur. If the date range passes and the regime change does not occur, the model is wrong in a way that registers as wrong, not as needing a parameter refinement.
This is an architectural feature missing from current AI forecasting. METR’s doubling-horizon work commits to a functional form (exponential) and a parameter (the doubling rate), but does not commit in advance to which observations would force them to abandon the framework rather than adjust the parameter. Sornette’s LPPLS commits to the functional form and to the failure condition simultaneously, because the functional form has the singularity baked in. If the singularity doesn’t arrive in the predicted window, you have a failed LPPLS.
A deeper Sornette contribution is the dragon-king. He argued, against the dominant black-swan framing, that the largest events in many complex systems are not random outliers from a power-law tail. They are products of distinct mechanisms (positive feedback loops, tipping points, bifurcations, and phase transitions) that operate only in specific regimes. The largest events are statistically distinguishable from the rest of the distribution because they come from a different generative process. This is consequential for AI forecasting because it inverts a common implicit assumption: that “transformative AI” lives on the same curve as “current AI,” just further along. Sornette’s framework says: maybe not. Maybe the transformative event, if it comes, is generated by a mechanism that does not appear in the current trajectory at all. Curve-fitting against the current trajectory cannot, in principle, predict events generated by mechanisms outside the trajectory.
There is a useful asymmetry in this view. Power-law extrapolation gives you no leverage on dragon-kings, but mechanism-based monitoring sometimes does. Sornette’s Financial Crisis Observatory (now here) monitors twenty-five thousand assets daily for log-periodic precursor signals: measurable features that show up before a phase transition, even when the timing within the precursor window is uncertain. He doesn’t predict the next grain that triggers the avalanche, he measures the pile’s slope.
The AI-forecasting equivalent would be to ask: what are the measurable precursors of a phase transition in AI capability? Specifically: “are the structural conditions that would enable a phase transition assembling themselves?” That is a different research program than curve-fitting.
Math
Demonstrating this requires some formal notation. Cover your eyes if you don’t like big equations. Here is the original LPPLS form as Sornette and Johansen wrote it for asset prices, roughly:
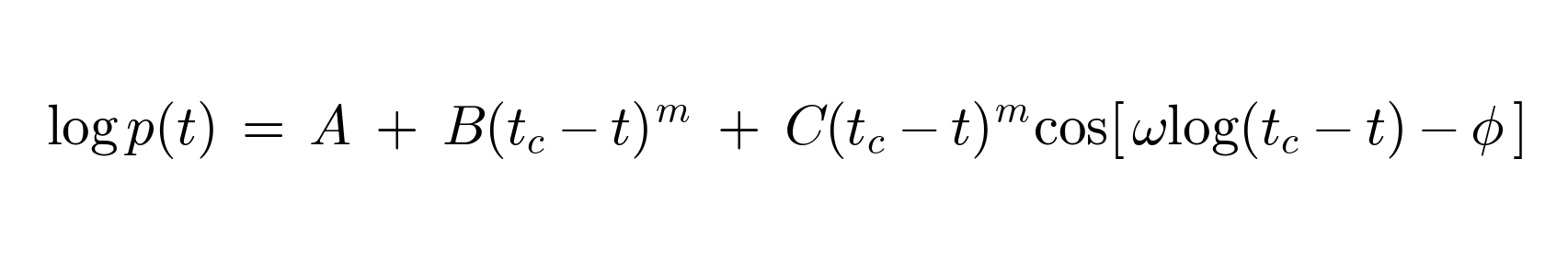
The formula has four moving parts:
An observable that grows (log of the asset price)
A critical time tc at which the regime shift is predicted to occur
A power-law term that captures faster-than-exponential acceleration toward tc
A log-periodic oscillation term that captures the discrete-scale-invariance signature of the precursor pattern
Phew. What? I’m going to convert it to the AI-structural version:
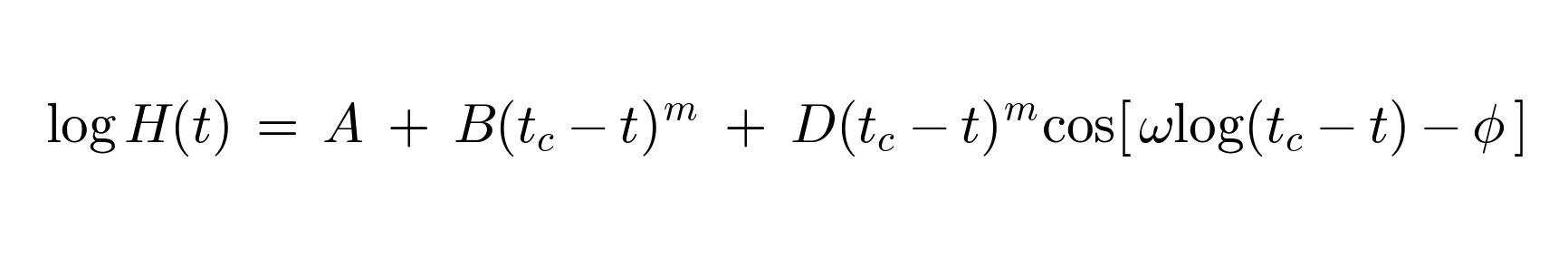
Still too abstract. We need an example, so we need to select H(t). Keep in mind that I am not an expert here, and choosing H(t) is structural. We can pick many things for H(t), so a real, deeper exploration would try several formulas on and rule out the ones the data doesn’t admit a sensible fit for after the first pass.
Let’s say H(t) is the log of METR’s time-horizon metric: the longest task duration, measured in human-minutes, that frontier AI systems can reliably complete. METR has been publishing this dataset since March 2025, with retroactive data going back further, and they fit it as an exponential with a roughly seven-month doubling time. We are going to take that same data and ask what LPPLS would commit us to if we used it instead. Now each parameter, translated:
H(t), the time-horizon of completable tasks. This is the load-bearing choice. I’m picking it because METR already publishes the data and the prior piece already engaged with their framework, but every other candidate metric (log-FLOPs, log-revenue, log of a benchmark composite, etc.) would yield a different model making different claims. A serious research program tries several and sees which ones the data even admits a sensible fit for. I’m picking one for demonstration.
A is a fitted intercept. It anchors the curve at the right log-minutes level. If frontier systems can reliably complete tasks taking on the order of an hour today, A ends up somewhere near log(60) in natural log, give or take, once the regression places it. It is not telling us anything diagnostic, just a number that fits the needs.
tc is the critical time at which the model claims a regime change occurs. This is the first substantive commitment. A forecaster fitting LPPLS to METR’s data commits to a specific date range for tc, say, “the fit places tc between 2028 and 2030.” If 2030 passes and no regime change has occurred, the model is wrong. This is the falsifier the doubling-horizon framework doesn’t have.
m is the criticality exponent. This is the second substantive commitment, and the one that distinguishes “AI is improving fast” from “AI is approaching a phase transition.” If the fitted m lands in roughly (0, 1), the data supports the criticality claim: the time-horizon is accelerating in the self-reinforcing, in a faster-than-exponential way that signals an approach to a singularity. If m lands at 1.5, the data is consistent with rapid growth but not with criticality, and the phase-transition narrative is falsified by the data even before tc arrives. METR’s current exponential fit is the special case where m is effectively 1 and the singularity term degenerates. LPPLS is the more general framework that lets the data tell you which regime you’re in.
B and D are fitted amplitudes. B scales the power-law term, D scales the oscillation envelope. Like A, they are numbers the regression needs, not diagnostic claims.
ω is the log-frequency of oscillation. This governs how fast the log-periodic precursor oscillations cycle as t approaches tc. Sornette’s empirical work on financial crashes consistently finds ω in a narrow range, around 6 to 8, across very different bubbles, which he interprets as evidence that the discrete-scale-invariance signature is real and universal. A forecaster applying this to AI commits to looking for an analogous oscillation pattern in the time-horizon data: small accelerations and pauses, getting closer together in real time as t approaches tc. If those oscillations don’t appear in the data, the criticality diagnostic doesn’t apply, regardless of what m comes out to. This is the third independent falsifier.
φ is a phase offset. Where in the oscillation cycle we happen to be at t = 0. Like A, B, and D, it is a fitted constant doing structural work without carrying its own claim.
So the substantive commitments are H(t) (the metric choice), tc (the date), m (the criticality regime), and ω (the oscillation signature). Four falsifiable claims, three of which can fire before tc arrives. Compare to the doubling-horizon framework: one functional form, one parameter, zero failure conditions that fire before the prediction window closes.
I am not fitting this model to METR’s data. I am not predicting a tc. I am showing what a forecaster would have committed to if they wanted to make the phase-transition claim about AI capability using a framework that submits to its own falsifiers. The work of actually running the fit, checking whether m even lands in the criticality range, checking whether the log-periodic oscillations are present in the data, is real research. It is not what this essay is doing. I am just trying to show that the framework exists, that it is not exotic, and that committing to it would mean committing to specific observations that would force retraction. METR’s framework does not commit to any such observations. That is the difference the prior piece was pointing at, made concrete.
Why would an AI capability dataset actually stutter and oscillate as it accelerates towards tc ?
The mechanism transfers from finance to AI more cleanly than it might first appear. In markets, log-periodic oscillations come from hierarchically organized traders alternating between imitating each other and trying to anticipate each other: each imitation-correction cycle a step toward the critical state, with cycles compressing in real time because the dynamics are operating on time-to-criticality rather than calendar time.
Frontier AI development has analogous structures. A small number of labs watch each other, alternating between racing-to-publish phases (rapid capability releases, copycat scaling, and infrastructure buildouts) and pause-and-digest phases (safety reviews, training runs, and capital-raising rounds). If competitive pressure compounds as it does in market bubbles, each cycle may be shorter than the last. If the field is genuinely approaching a regime change, the framework predicts this compression continues along a log-periodic schedule rather than a linear or simple-exponential one: small accelerations and pauses, getting closer together in real time as t approaches tc. If we instead observe roughly evenly-spaced release cycles, or accelerating-but-not-log-periodic compression, the criticality diagnostic doesn’t apply. Lots of “ifs” here, so be careful.
What does this look like concretely? If H(t) is the time-horizon metric and m lands in the criticality range, the model is claiming that the longest-task-completable quantity itself is approaching a saturation point: a date at which "the longest task frontier systems can do" stops being a finite, meaningful number, because the metric ceases to bound the systems. The criticality regime is not making the philosophical claim of "AGI" or "the singularity"; it is making the much narrower claim that this specific operationalization of capability stops being a useful measurement. The non-criticality regime, by contrast, is METR's current picture: roughly seven-month doublings continuing indefinitely, with time-horizon a finite and meaningful quantity for the foreseeable future. The log-periodic stuttering (accelerating release cycles compressing in real time) is the data signature that distinguishes the first picture from the second. If we see the compression, the saturation claim is on the table. If we don't, METR's bounded-doubling picture holds and the phase-transition narrative is the wrong frame for what is actually happening.
So can we point to what we see so far and make a call? The honest answer is no. The diagnostic lives in fitted values of m and ω, with confidence intervals, on a time series long enough to support seven-parameter estimation. METR’s dataset is public but too short for seven-parameter estimation with confidence intervals. Pattern-matching log-periodicity by eye from a handful of release dates is precisely the vibes-forecasting my prior piece argued against. I am not going to do that here.
What I will commit to publicly:
if a competent practitioner fits LPPLS to METR’s dataset over the next twelve months and reports m outside (0, 1), or fails to find log-periodic structure at conventional significance, I will treat the criticality-saturation hypothesis as not-on-the-table for this operationalization and say so in writing. If they find m in (0, 1) with significant log-periodic structure and a tc range that survives out-of-sample testing, I will treat the hypothesis as live and update my own forecasts accordingly.
The point
LPPLS deserves a place in this conversation. It offers a built-in falsifier, it applies to systems no less complex than AI, and it provides multiple independent failure conditions: the three things my prior piece’s criterion demanded. It has 30 years of prior work behind it. It is worth being considered against METR's time-horizon work, Epoch AI's compute-scaling laws, and the AI Futures Project's scenario modeling. Whether it will turn out to be the right framework for AI capability is an open question.
Hard work is being done on rigorous models, and it’s not being heard enough.
Footnotes/citations
[1] Anbar Jafari, A., Ozcinar, C., & Anbarjafari, G. (2025). A Mathematical Framework for AI Singularity: Conditions, Bounds, and Control of Recursive Improvement. arXiv:2511.10668.